ABNF
ABNF is a syntax to describe phrases, a phrase being any string of integer character codes. Because the character codes so often represent the ASCII character set there are special ABNF features to accommodate an easy description of ASCII strings. However, the meaning and range of the character code integers are entirely up to the user. The complete ABNF syntax description of a phrase is called a grammar and the terms "grammar" and "ABNF syntax" will be used synonymously here.
What follows is description of the salient features of ABNF. If there are any differences between what is represented here and in RFC 5234, the RFC naturally prevails.
Rules
Phrases are described with named rules. A rule name is alphanumeric with hyphens allowed after the first character. Rule names are case insensitive. A rule definition has the form:
name = elements CRLF
where the equal sign, =, separates the name from the phrase definition. Elements are made up of terminals, non-terminals and other rule names, as described below. Each rule must end with a carriage return, line feed combination, CRLF. A rule definition may be continued with continuation lines, each of which begins with a space or tab.
Terminals
Rules resolve into a string of terminal character codes. ABNF provides several means of representing terminal characters and strings of characters explicitly.
single characters
%d32 - represents the decimal integer character code 32 %x20 - represents the hexidecimal integer character code 20 or decimal 32 %b100000 - represents the binary integer character code 100000 or decimal 32
strings of characters
%d13.10 - represents the line-ending character string CRLF. %x0D.0A - represents the line-ending character string CRLF. %b1101.1010 - represents the line-ending character string CRLF.
range of characters
%d48-57 - represents any single character code in the decimal range 48 through 57
that is, any ASCII digit 0, 1, 2, 3 ,4, 5, 6, 7, 8 or 9
%x30-39 - represents any single character code in the hexidecimal range 30 through 39
(also any ASCII digit)
%b110000-111001 - represents any single character code in the binary range 110000 through 111001
(also any ASCII digit)
literal strings of characters
Because of their frequency of use, there is also a notation for literal strings of printing, 7-bit ASCII characters.
"ab" - represents the case-insensitive string "ab" and would match
%d97.98, %d65.98, %d97.66 or %d65.66 ("ab", "Ab", "aB" or "AB")
%i"ab" - defined in RFC 7405, is a case-insensitive literal string (identical to "ab")
%s"ab" - defined in RFC 7405, is a case-sensitive literal string (identical to %d97.98)
Tab characters, 0x09, are not allowed in literal strings.
prose values
When all else fails, ABNF provides a means for the grammar's author to simply provide a prose explanation of the phrase in the form of a spoken, as opposed to formal, language. The notation is informative and the parser generator will recognize it as valid ABNF. However, since there are no formal specifics, the generator will halt without generating a parser.
<phrase description in prose>
Tab characters, 0x09, are not allowed in the prose values.
Non-Terminals
concatenation
A space between elements in a rule definition represents a concatenation of the two elements. For example, consider the two rules,
AB1 = "a" "b" CRLF AB2 = "ab" CRLF
The space between the two elements "a" and "b" acts as a concatenation operator. The effect in this case is that rule AB1 defines the same phrase as rule AB2.
alternatives
The forward slash, /, is the alternative operator. The rule
AB = "a" / "b" CRLF
would match either the phrase a or the phrase b.
incremental alternatives
While not a new operation, incremental alternatives are a sometimes-convenient means of adding alternatives to a rule.
alt1 = "a" / "b" / "c" CRLF
alt2 = "a" CRLF
/ "b" CRLF
/ "c" CRLF
alt3 = "a" / "b" CRLF
alt3 =/ "c" CRLF
Rules alt1, alt2 and alt3 have identical definitions. The incremental alternative, =/, allows for adding additional alternatives to a rule at a later date. As seen in alt2, the same affect can be achieved with line continuations. However, in some cases, it may be convenient or even essential to add additional alternatives later in the grammar. For example, if the grammar is broken into two or more files. In such a case, line continuations would not be possible and the incremental alternative becomes an essential syntactic addition.
repetitions
An element modifier of the general form n*m (0 <= n <= m) can be used to indicate a repetition of the element a minimum of n times and a maximum of m times. For example, the grammar
number = 2*3digit CRLF digit = %d48-57 CRLF
would define a phrase that could be any number with 2 or 3 ASCII digits. There are a number of shorthand variations of the repetition operator.
*= 0*infinity (zero or more repetitions) n*= n*infinity (n or more repetitions) *m= 0*m (zero to m repetitions) n = n*n (exactly n repetitions)
Groups
Elements may be grouped with enclosing parentheses. Grouped elements are then treated as a single element within the full context of the defining rule. Consider,
phrase1 = elem (foo / bar) blat CRLF phrase2 = elem foo / bar blat CRLF phrase3 = (elem foo) / (bar blat) CRLF
phrase1 matches elem foo blat or elem bar blat, whereas phrase2 matches elem foo or bar blat. A word of caution here. Concatenation has presidence over (tighter binding than) alternation so that phrase2 is the same as phrase3 and not phrase1. It can be confusing. Use parentheses liberally to keep the grammar meaning clear.
Another useful way to think of groups is as anonymous rules. That is, given
phrase1 = elem (foo / bar) blat CRLF phrase2 = elem anon blat CRLF anon = foo /bar CRLF
phrase1 and phrase2 are identical. Only phrase2 utilizes the explicit rule anon for the parenthesized grouping. In phrase1, the parenthesized grouping anonymously defines the same rule as anon.
Optional Groups
Elements grouped with square brackets, [], are optional groups. Consider,
phrase1 = [elem foo] bar blat CRLF phrase2 = 0*1(elem foo) bar blat CRLF
Both phrases are identical and will match either elem foo bar blat or bar blat.
Comments
Comments begin with a semicolon, ;, and continue to the end of the current line. For example, in the following rule definition, everything from the semicolon to CRLF is considered white space.
phrase = "abc"; any comment can go here CRLF
In this implementation empty lines and comment-only lines are accepted as white space, but any line beginning with one or more space/tab characters and having text not beginning with a semicolon will be rejected as an ABNF syntax error. Consider the lines,
1:CRLF 2: CRLF 3:;comment CRLF 4: ; comment CRLF 5: comment CRLF
Lines 1: through 4: are valid blank lines. Line 5: would be regarded as a syntax error.
Bringing it all together now
Here is an example of a complete ABNF grammar representing the general definition of a floating point number.
float = [sign] decimal [exponent]
sign = "+" / "-"
decimal = integer [dot [fraction]]
/ dot fraction
integer = 1*%d48-57
dot = "."
fraction = 1*%d48-57
exponent = "e" [esign] exp
esign = "+" / "-"
exp = 1*%d48-57
Restrictions
This APG implementation imposes a several restrictions and changes to the strict ABNF described above. These are minor changes except for the disambiguation rules.
Indentations
RFC 5234 specifies that a rule may begin in any column, so long as all rules begin in the same column. This implementation restricts the rules to the first column.
Line Endings
RFC 5234 specifies that a line ending must be the carriage return/line feed pair, CRLF. This implementation relaxes that and accepts CRLF, LF or CR as a valid line ending. However, the last line must have a line ending or a fatal error is generated. (Forgetting a line ending on the last line is a common and annoying error, but keeping the line ending requirement has been a conscious design decision.)
Case-Sensitive Strings
This implementation allows case-sensitive strings to be defined with single quotes.
phrase1 = 'abc' CRLF phrase2 = %s"abc" CRLF phrase3 = %d97.98.99 CRLF
All three of the above phrases defined the identical, case-sensitive string abc. The single-quote notation for this was introduced in 2011 prior to publication of RFC 7405. The SABNF single-quote notation is kept for backward compatibility.
Empty Strings
As will be seen later, some rules may accept empty strings. That is, they match a string with 0 characters. To represent an empty string explicitly, two possibilities exist.
empty-string = 0*0element ; zero repetitions empty-string = "" ; empty literal string
In this implementation only the literal string is allowed. Zero repetitions will halt the parser generator with a grammar error.
Disambiguation
The ALT operation allows the parser to follow multiple pathways through the parse tree. It can be and often is the case that more than one of these pathways will lead to a successful phrase match. The question of what to do with multiple matches was answered early in the development of APG with the simple rule of always trying the alternatives left to right as they appear in the grammar and then simply accepting the first to succeed. This "first success" disambiguation rule may break a strictly context-free aspect of ABNF, but it not only solves the problem of what to do with multiple matches, at least on a personally subjective level, it actually makes the grammars easier to write. That is, easier to arrange the alternatives to achieve the desired phrase definitions.
Related to disambiguation is the question of how many repetitions to accept. Consider the grammar
reps = *"a" "a" CRLF
A strictly context-free parser should accept any string an, n>0. But in general this requires some trial and error with back tracking. Instead, repetitions in APG always accept the longest match possible. That would mean that APG would fail to match the example above. However, a quick look shows that a simple rewrite would fix the problem.
reps = 1*"a" CRLF
Longest-match repetitions rarely lead to a serious problem. Again, knowing in advance exactly how the parser will handle repetitions allows for easy writing of a correct grammar.
ABNF as a Tree of Node Operations
APG was originally developed with the recognition that the ABNF syntax elements could be represented with a tree of node operations. That is, every ABNF grammar can be represented as a tree of seven types of node operations, three terminal and four non-terminal.
- TLS - The TLS, or terminal literal string, operation is simply to match or capture the alphabet characters in the input, source string as defined in the grammar. The match is done in a case-insensitive manner for ASCII alphabetic characters.
- TBS - The TBS, or terminal binary string, operation. Same as TLS except that the characters are matched character-for-character with no special ASCII considerations.
- TRG - The TRG, or terminal range, operation matches, or captures, any alphabet character in the grammar-defined range.
- ALT - The ALT node provides a list of alternate paths for the parser, one for each child node.
- CAT - The CAT node dictates concatenating the results of all child nodes.
- REP - The REP node, within grammar-defined limits, dictates that the child node be repeated, the results of each repetition being concatenated to the previous result.
- RNM - The RNM, or rule, node operation is to substitute it with the node operations defined by the named rule.
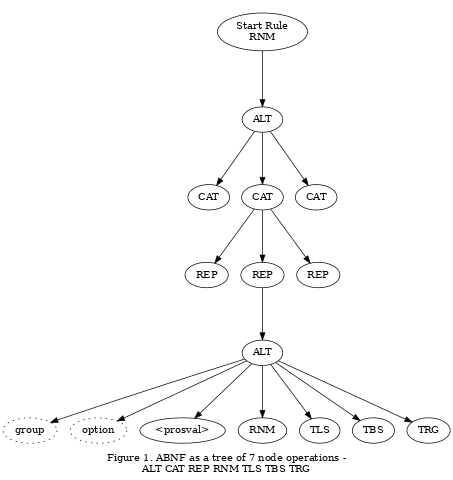
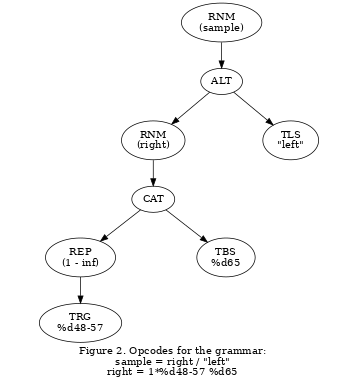
The ABNF syntax defines a tree of general node operations as illustrated in figure 1. An ABNF grammar then reduces this to a specific tree of node operations as illustrated in figure 2 for the sample grammar below. A depth-first traversal of the grammar-specific tree, with the node operations as the guide, then is the APG recursive-descent parser. Figure 2 illustrates the grammar-specific tree of opcodes for the sample grammar
sample = right / "left" right = 1*%d48-57 %d65
Superset ABNF (SABNF)
In addition to the seven original node operations defined by ABNF, APG recognizes an addition 8 operations. Since these do not alter the original seven operations in any way, these constitute a super set of the original set. Hence the designation Superset Augmented Backus-Naur Form, or SABNF.
The user-defined terminals and look ahead operations have been carried over from previous versions of APG. Look behind, anchors and back references have been developed to replicate the phrase-matching power of various flavors of regex. However, the parent mode of back referencing is, to my knowledge, a new APG development with no previous counterpart in other parsers or phrase-matching engines.
User-Defined Terminals
In addition to the ABNF terminals above, APG allows for User-Defined Terminals (UDT). These allow the user to write any phrase he or she chooses as a code snippet. The syntax is,
phrase1 = u_non-empty CRLF phrase2 = e_possibly-empty CRLF
UDTs begin with u_ or e_. The underscore is not used in the ABNF syntax, so the parser can easily distinguish between UDT names and rule names. The difference between the two forms is that a UDT beginning with u_ may not return an empty phrase. If it does the parser will throw an exception. Only if the UDT name begins with e_ is an empty phrase return accepted. The difference has to do with the rule attributes and will not be discussed here further.
Note that even though UDTs are terminal phrases, they are also named phrases and share some named-phrase qualities with rules.
Look Ahead
The look ahead operators are modifiers like repetitions. They are left of and adjacent to the phrase that they modify.
phrase1 = &"+" number CRLF phrase2 = !"+" number CRLF number = ["+" / "-"] 1*%d48-75 CRLF
phrase1 uses the positive look ahead operator. If number begins with a "+" then &"+" returns the empty phrase and parsing continues. Otherwise, &"+" return failure and phrase1 fails to find a match. That is, phrase1 accepts only numbers that begin with +. e.g. +123.
phrase2 uses the negative look ahead operator. It works just as described above except that it succeeds if "+" is not found and fails if it is. That is, phrase2 accepts only numbers with no sign or with a negative sign. e.g. -123 or 123.
A good discussion of the origin of these operators can be found in this Wikipedia article.
Look Behind
The look behind operators are modifiers very similar to the look ahead operators, the difference, as the name implies, is that they operate on phrases behind the current string index instead of ahead of it.
phrase1 = any-text &&line-end text CRLF phrase2 = any-text !!line-end text CRLF text = *%d32-126 CRLF any-text = *(%d10 / %d13 / %d32-126) CRLF line-end = %d13.10 / %d10 / %d13 CRLF
phrase1 will succeed only if text is preceded by a line-end. phrase2 will succeed only if text is not preceded by a line-end.
Look behind was introduced specifically for apgex, the phrase-matching engine. It may have limited use outside this application.
Back References
Back references are terminal strings similar to terminal literal and binary strings. The difference is that terminal literal and binary strings are predefined in the grammar syntax whereas back reference strings are dynamically defined with a previous rule name or UDT matched phrase. The basic notation is a backslash, \, followed by a rule or UDT name.
phrase1 = A \A CRLF phrase2 = A \%iA CRLF phrase3 = A \%sA CRLF phrase4 = u_myudt \u_myudt A = "abc" / "xyz" CRLF
The back reference \A will attempt a case-insensitive match to a previously matched by A-phrase. (The notation works equally for rule names and UDT names.) Therefore, phrase1 would match abcabc or abcABC, etc., but not abcxyz. The %i and %s notation is used to indicate case-insensitive and case-sensitive matches, just as specified in RFC 7405 for literal strings. Therefore, phrase3 would match xYzxYz but not xYzxyz.
These back reference operations were introduced specifically for apgex to match the parsing power of various flavors of the regex engines. However, it was soon recognized that another mode of back referencing was possible. The particular problem to solve was, how to use back referencing to match tag names in opening and closing HTML and XML tags. This led to the development of a new type of back referencing, which to my knowledge, is unique to APG.
I'll refer to the original definition of back referencing above as "universal mode". The name "universal" being chosen to indicate that the back reference \%uA matches the last occurrence of A universally. That is, regardless of where in the input source string or parse tree it occurs.
I'll refer to the new type of back referencing as "parent mode". The name "parent" being chosen to indicate that \%pA matches the last occurrence of A on a sub-tree of the parse tree with the same parent node. A more detailed explanation is given here.
Case insensitive and universal mode are the defaults unless otherwise specified. The complete set of back references with modifiers is:
\A = \%iA = \%uA = \%i%uA = \%u%iA \%sA = \%s%uA = \%u%sA \%pA = \%i%pA = \%p%iA \%s%pA = \%p%sA
Anchors
Again, to aid the pattern matching engine apgex, SABNF includes two specific anchors, one for the beginning of the input source string and one for the end.
phrase1 = %^ text CRLF phrase2 = text %$ CRLF phrase3 = %^ "abc" %$ CRLF text = *d32-126 CRLF
Anchors match a location, not a phrase. %^ returns an empty string match if the input string character index is zero and fails otherwise. Likewise, %$ returns an empty string match if the input string character index equals the string length and fails otherwise. The notations %^ and %$ have been chosen to be similar to their familiar regex counterparts.
In the examples above, phrase1 will match text only if it starts at the beginning of the string. phrase2 will match text only if it ends at the end of a string. phrase3 will match abc only if it is the entire string. This may seem self evident in this context, but APG 7.0 allows parsing of sub-strings of the full input source string. Therefore, when parsing sub-strings it may not always be known programmatically whether a phrase is at the beginning or end of a string.
Operator Summary
| operator | notation | form | description |
|---|---|---|---|
| TLS | "string" | ABNF | terminal literal string |
| TBS | %d65.66.67 | ABNF | terminal binary string |
| TRG | %d48-57 | ABNF | terminal range |
| UDT | u_name or e_name |
SABNF | User-Defined Terminal |
| BKR | \name or \u_name |
SABNF | back reference |
| ABG | %$ | SABNF | begin of string anchor |
| AEN | %^ | SABNF | end of string anchor |
| operator | notation | form | description |
|---|---|---|---|
| ALT | / | ABNF | alternation |
| CAT | space | ABNF | concatenation |
| REP | n*m | ABNF | repetition | RNM | name | ABNF | rule name |
| AND | & | SABNF | positive look ahead |
| NOT | ! | SABNF | negative look ahead |
| BKA | && | SABNF | positive look behind |
| BKN | !! | SABNF | negative look behind |
