While the generator is parsing an SABNF grammar there is much that it can determine about the generated parser's performance independent of what input source string it might be parsing. From an examination of all terminals – strings and ranges – it can determine the set of alphabet characters that the grammar-defined language will accept. It is also possible for each terminal node to build a map of whether or not it accepts or rejects each character. Each map entry has four states:
- MATCH, (M), the node accepts the single character as a full match to the node
- NOMATCH, (N), the node does not accept the character
- EMPTY, (E), the node does not accept the character but does accept the empty string
- ACTIVE, (A), the node will accept the character as the first character of a longer phrase, but the parser must continue to discover whether that full phrase is or is not matched
Additionally, once the maps for the terminal nodes are known, the generator can walk the parse tree for the specified grammar and build maps for all nodes in the branches above the terminals. Often this results in a determinate parse from a non-terminal node higher in the parse tree. Sometimes as high as the root node – the start rule.
Consider the simple grammar:
S = "a" / "bc" CRLF
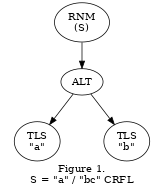
It is simple to see from observation that the grammar's character set is [a, A, b, B, c, C].
- the TLS("a") map is [M, M, N, N, N, N]
- the TLS("bc") map is [N, N, A, A, N, N]
- the ALT map is [M, M, A, A, N, N]
- the RNM map is [M, M, A, A, N, N]
For the input string "a" or "A" the parser never needs to descend the parse tree at all. From the PPPT map for the start rule these two characters are accepted. However, for the characters "b" and "B" the parser knows that there is a possibility of a match and must fully descend the parse tree to find out. For characters "c", "C" or any other character not in the alphabet set, the start rule and the parse fail immediately without need of descent.
This simple example illustrates how PPPT maps work. The generator will build the maps and the parser will use them for a single-character look ahead to improve parser performance.
Experience has shown PPPT maps will reduce the number of node hits on average of about 68%. However, the map lookups are not free and the actual reduction in parsing times are more like 50%. That is, parsing times are cut in half.
Limitations
The trade off with PPPT maps is, of course, memory. Since there are only four PPPT states per node, only 2 bits are required per state. In theory, the PPPT states for four nodes could be squeezed into each byte. In practice, the bit packing and unpacking slows the map look up and a full byte is actually used for each state and node.
Large grammars produce an even larger number of parse tree nodes. But the real problem is with the character set. Consider, for example, a grammar that accepts the full range of UTF-32 characters. With over a million characters in the alphabet character set, this would mean a megabyte for each parse tree node. It's not unusual for a grammar to generate 1000 or more nodes, in which case the PPPT maps for this character set would require a gigabyte or more of data storage.
Therefore, memory considerations are necessary before choosing to generate PPPT data for a parser. As an aid in this consideration is the function vApiPpptSize(). It can be called any time after vApiOpcodes() which is where the alphabet character set range and other relevant sizes are computed.
